The Gemini Spark Reporting Problem
I want to be honest with you up front. I can't access it either. And that is exactly the point of this post.

Most of the Gemini Spark takes in your real estate feed this week were written by people who can’t access Gemini Spark.
I want to be honest with you up front. I can’t access it either. And that is exactly the point of this post.
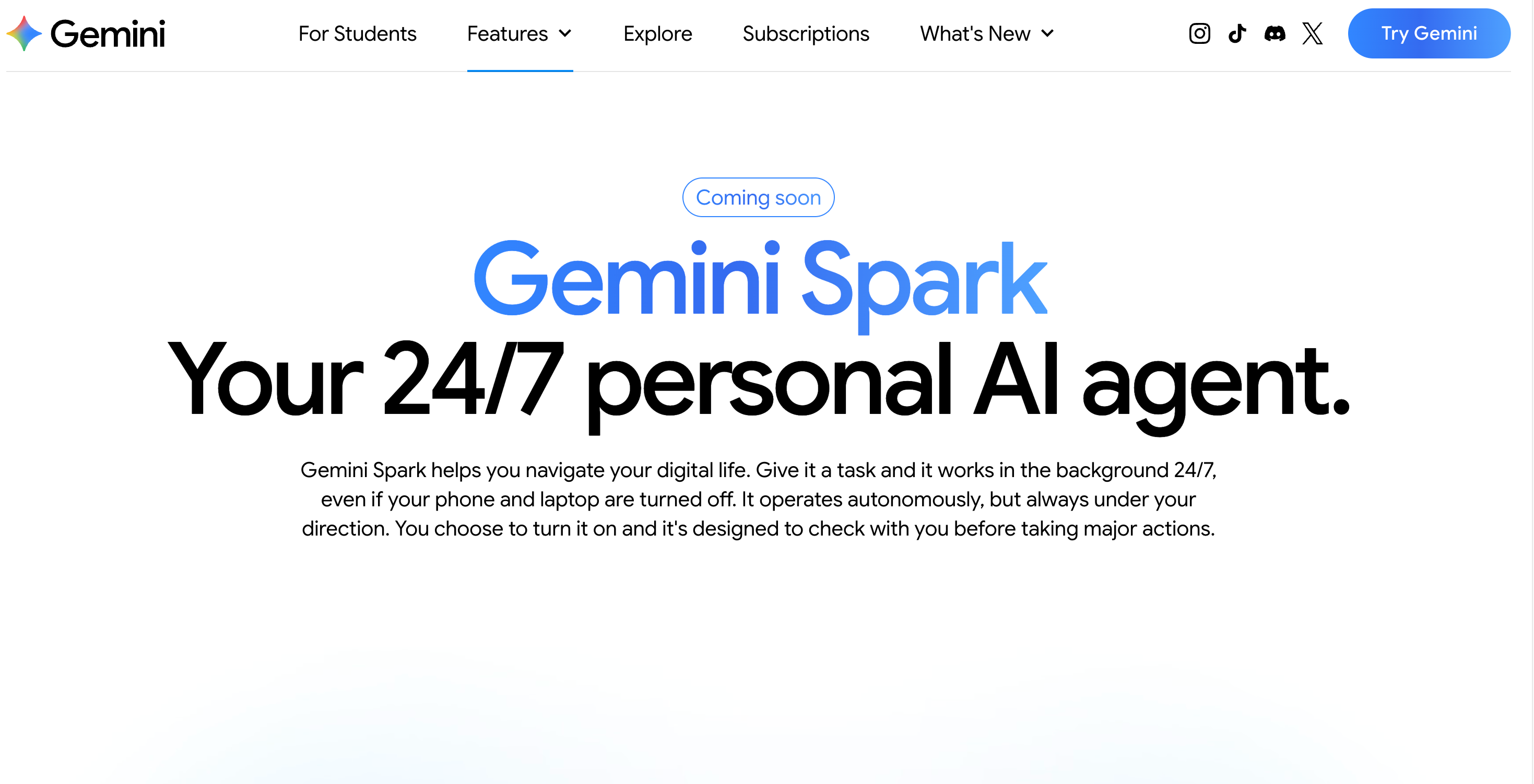
Google announced Spark at I/O on May 19. By Wednesday afternoon, the real estate AI corner of LinkedIn and Facebook was already full of “what this means for agents” posts, breakdown carousels, and confident hot takes about how Spark will change the business. The catch is that almost none of those creators have actually used it. The rollout is staged. Trusted testers first, then U.S. Google AI Ultra subscribers, with broader access on a vague timeline. If you’re outside the trusted tester group and don’t pay for Ultra, you have read about Spark. That’s it.
This is a Decomposition problem. When you cannot separate what is known from what is speculated, you do not have an analysis. You have vibes.
So let me walk through what is actually settled, what is not, and how I’m thinking about Spark for our business before I get my hands on it.
Subscribe if you want this kind of breakdown in your inbox every week. No hype. Just the work.
What Spark Actually Is (The Rules Layer)
Strip away the marketing and Spark is a persistent agent runtime built on Gemini 3.5 Flash and Google’s Antigravity platform. The agent runs continuously on a Google Cloud virtual machine, which means it keeps working when your phone is asleep and your laptop is closed. That cloud persistence is the genuine architectural difference from a chatbot.
What it can do at launch, according to Google’s own documentation:
Monitor Gmail and draft replies in your writing style
Pull threads from multiple Workspace documents and synthesize them
Organize calendar, tasks, and recurring workflows
Take actions through partner integrations (Canva, OpenTable, Instacart at launch, with Zillow and others in the MCP partner rollout coming over the summer)
There is a confirmation gate for high-stakes actions. Spark is supposed to ask before sending an email, completing a purchase, or modifying your calendar. Google’s exact phrasing in the official documentation, which is worth reading carefully, is that Spark “can do things like share your information or make purchases without asking.” That is Google’s own disclosure. Not a critic’s framing.
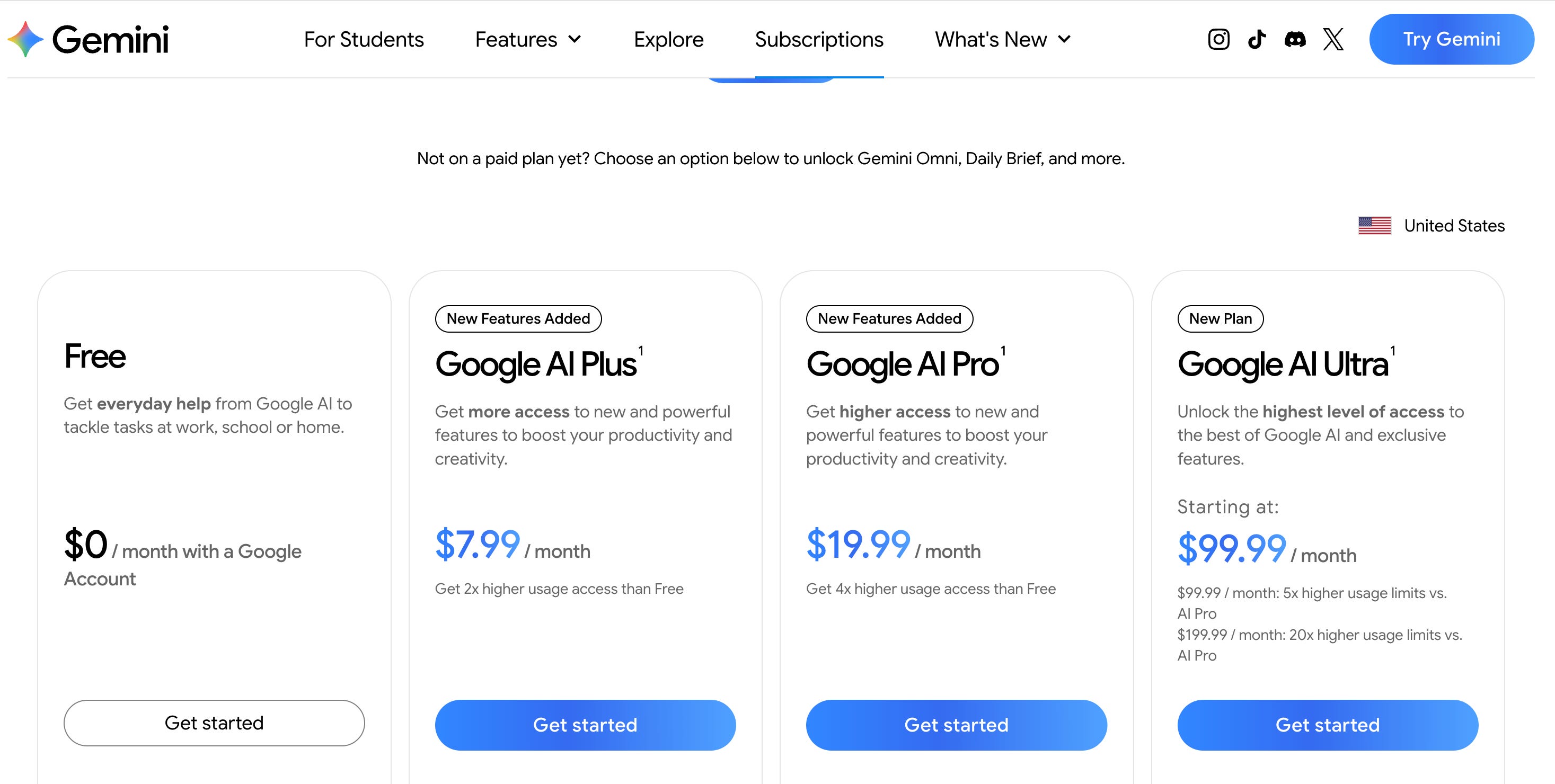
Pricing changed at I/O too, and the early Perplexity-style summaries floating around have this wrong. Google AI Ultra is no longer $250 per month. Google introduced a $99.99 entry tier and dropped the top tier to $199.99. Spark is included in both, U.S. only at launch.
What We Don’t Know (The Judgment Layer)
This is where most of the current coverage gets sloppy. The honest list of unknowns is long.
We don’t know how Spark performs on the messy, non-Workspace tools most agents actually live in. CRMs, transaction management platforms, MLS interfaces, e-signing systems. Spark is heavily tuned for Google’s ecosystem. If your business runs on Follow Up Boss, Dotloop, Lofty, and a state-specific MLS, the “transformative” reviews from Workspace-native testers do not necessarily port to you.
We don’t know how it handles real client data over weeks of use. The early reviews are demo-fresh. The interesting failure modes show up at week six, not week one.
We don’t know how it behaves with Fair Housing-sensitive content. An agent runtime that drafts emails in your voice, monitors inbound communication, and acts on your behalf is a TREC and HUD compliance question waiting to happen. Nobody in the current coverage has stress-tested this.
We don’t know what the data exposure surface actually looks like in practice. Spark needs access to email, calendar, documents, and increasingly payment methods. Google has flagged this themselves. The bigger your client list, the bigger the question.
A reasonable creator looking at that list would write a “here is what to watch for when you can test it” post. Most are skipping that step and writing the conclusion first.
Why This Pattern Keeps Happening in Real Estate AI Content
The real estate AI content economy rewards speed over accuracy. A LinkedIn post the day of an announcement gets reach. A measured post six weeks later, written after actually using the tool, does not. So creators race to be first, and “first” in AI coverage means writing about something you have not touched.
This is not new. We saw it with Sora when most creators couldn’t access it. We saw it with Claude Cowork. We saw it with every ChatGPT agent feature release. The pattern is consistent: announcement, immediate explainer wave from people without access, then a much smaller, much later wave of real practitioner reviews after the tool has been in production for a month.
The Decomposition lesson here is simple. When you read AI coverage, ask one question: does this person have access, or are they reading the same blog posts I could read? If they don’t have access, the “what this means for your business” section is not analysis. It is extrapolation dressed up to look like analysis.
What I’m Doing Until I Can Test It
Three things, in this order.
First, I’m not paying $99.99 a month for Ultra just to chase Spark in beta. Our stack already covers most of what Spark does at the demo level. Claude handles agentic work across our writing, listing analysis, and email drafting. The marginal value of adding Spark before it has matured is low. The marginal cost of context-switching is real.
Second, I’m watching the MCP partner rollout this summer. The day Spark gets useful MLS, CRM, or e-sign integrations is the day this conversation changes for our business. Until then, the partner list is mostly consumer apps.
Third, I’m logging the questions I want answered when I do get access. How does it handle Fair Housing-sensitive drafting. How does it behave when monitoring an inbox with active transaction communication. How does it perform on a Texas-specific contract review. Those are the tests. Not “did it summarize my Gmail.”
If you’re feeling pressure to publish a Spark take this week, the strongest move is the one almost nobody is making: say what you know, say what you don’t, and tell your audience you’ll come back to it after you’ve actually used it.
That is the entire job.
If this kind of breakdown is useful, subscribe to The Decomposition. New posts every week, written from active production work in residential and land, not from a coaching deck.
Exactly my take.